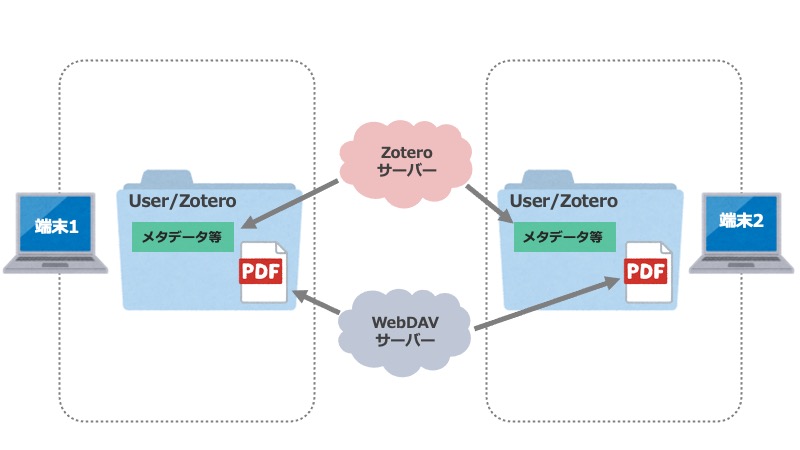
数学が苦手なうちのJKに、将来必要となるかもしれないデータ分析への抵抗感をなくしてもらう目的で記事を書くことにしました。
前回のおさらい
前編では、グラフを
- 軸をどうやって表すか(縦軸・横軸・色など)
- 軸に何を割り当てるか
という観点で整理しようという抽象的な話をしました。
今日は具体例を見ていきましょう。
変数が1つのとき
1つの質的変数を示す
あるクラスの血液型の分布を例にして考えてみます。 1つ目の軸には変数が取る値を割り当てます。質的変数は、2つ目の軸を使って個数・割合をで示さないといけないんでしたね。整理すると次のように書けます。
- 1つ目の軸:A型、B型、O型、AB型
- 2つ目の軸:それぞれの血液型に属する人数(または全体に占める割合)
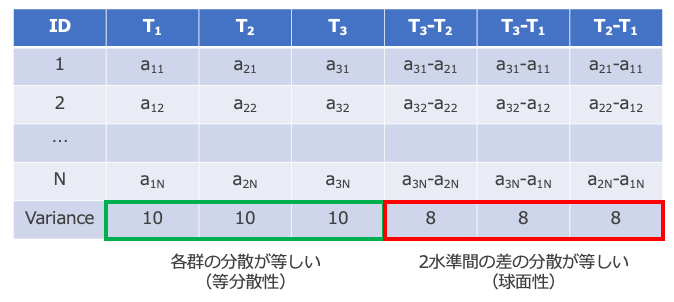
カテゴリー毎の個数や割合を、高さで表せば、棒グラフ(bar chart)、 長さで表せば水平棒グラフ、角度(つまり弧の長さ)で表せば、円グラフ(pie chart)になります。 これらは表したいものは同じで、見せ方が違うだけなんです。
では、棒グラフと円グラフ、どちらを使う方が良いんでしょうか?
円グラフの方が人気がありますが、原則として棒グラフを使います。円グラフだと微妙な大小関係が読み取りにくいからです。先程のグラフで、B型とO型のどちらが多いか、円グラフから読み取れますか?
例外としては、「あるカテゴリーがこんなに占めてますよ!」みたいなことをアピールしたいときは円グラフの方がインパクトが出るかもしれませんね。
1つの量的変数を示す
量的変数はそのまま1つ目の軸で示すことができます。それぞれの値をプロット*1するか、それで見にくくなるなら要約値をプロットすればいいのです。
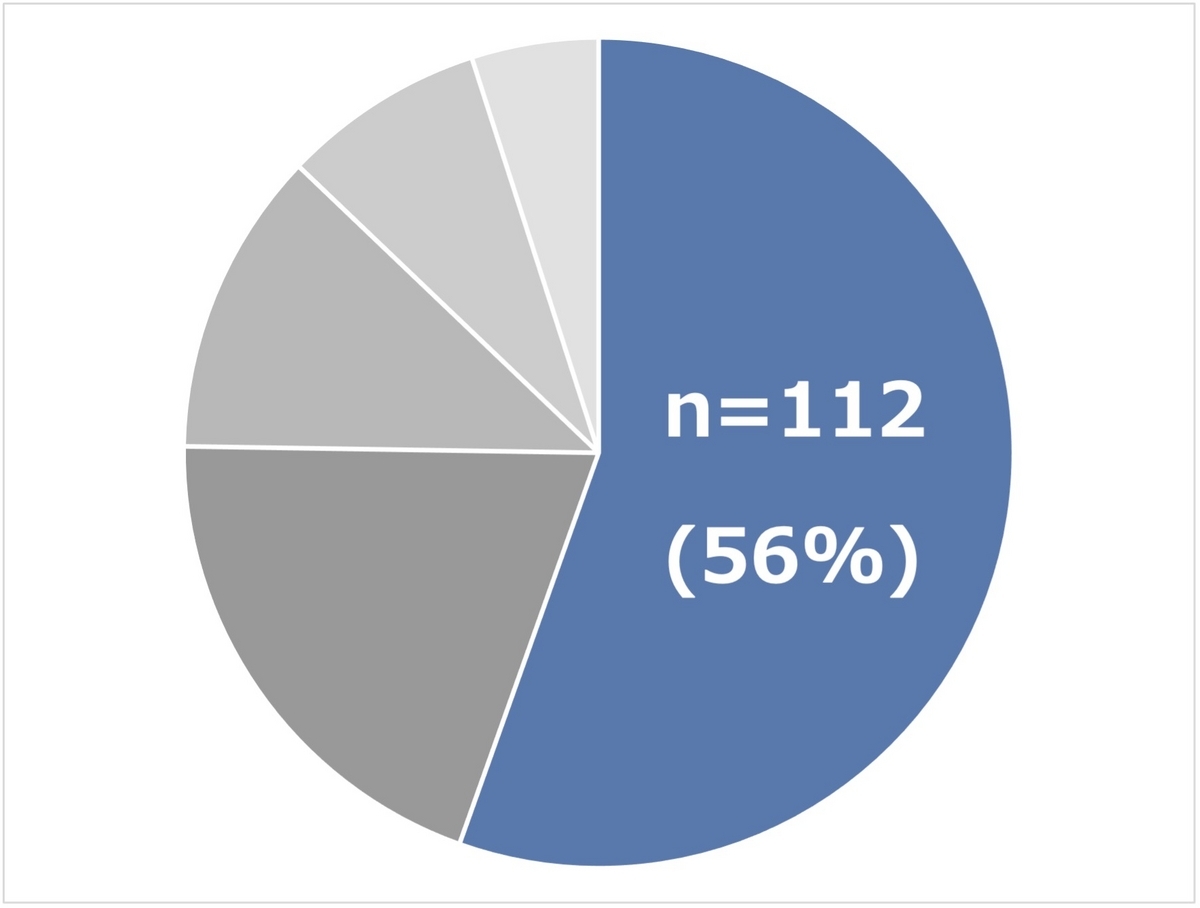
複数の要約値をまとめて示す方法として、箱ひげ図(box-whisker plot)という方法があります。 これは、中央値・四分位範囲(IQR)と外れ値の様子を分かりやすく示すことができるグラフです。
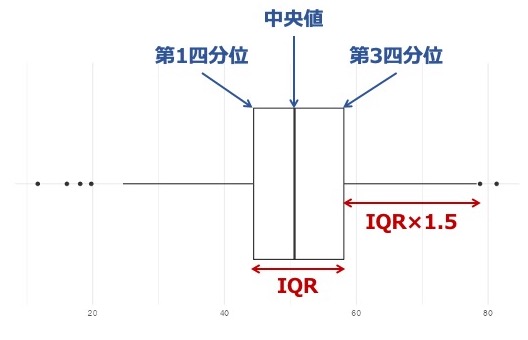
- 箱の中央線 = 中央値
- 箱の両端 = IQRの両端(第1四分位数、第3四分位数)
- 箱の両端から伸びるヒゲ = 第1四分位数(あるいは第3四分位数)の外にある点で、IQR×1.5以内にある点のうち、最も箱から遠いところを示す。
- 点 = 上記のヒゲよりも外側にある点
上記の加えて、平均値を示すこともできます。
もう1つの量的変数の示し方は、カテゴリー化する方法です。 例えば、年齢をそのまま使えば量的変数ですが、10代、20代、30代というカテゴリーで区別すれば、質的変数として扱うことになりますので、カテゴリー毎の人数を帯状にすれば下のようになります。
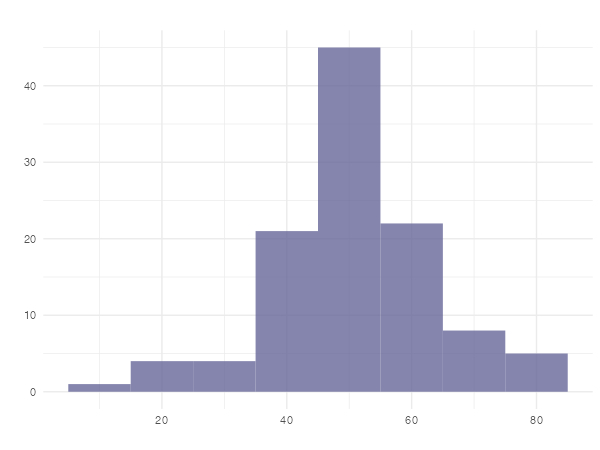
ヒストグラム(histogram)は棒グラフと似ていますが、隙間がない点が違います。量的変数をカテゴリー化すると、隣り合うカテゴリーは隙間なく連続しているからです。区間の右端が「以下」なのか「未満」なのか、統一して決めておかなければいけません。
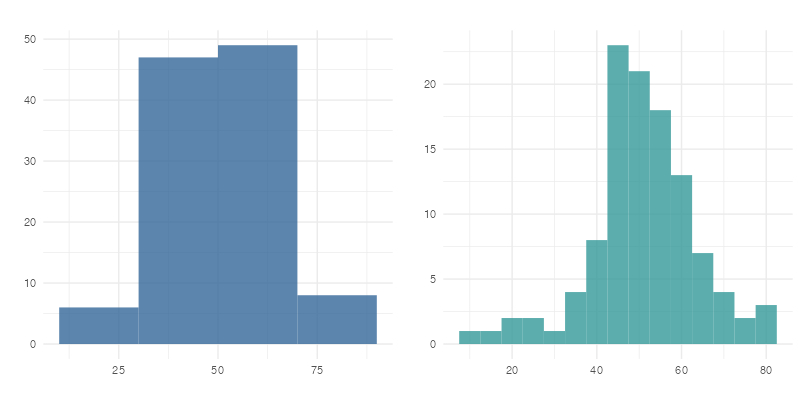
また、ヒストグラムでは区間の決め方によってグラフの印象が大きく変わることがあります。下の図では、同じデータを20歳刻み(左)と5歳刻み(右)で描きました。
ヒストグラムの親戚に密度プロット(density plot)というグラフがあります。これはヒストグラムの区間を限りなく小さくしながら、ヒストグラムのデコボコが滑らかな曲線になるようにしていったグラフです。

変数が2つのとき
2つの量的変数を示す
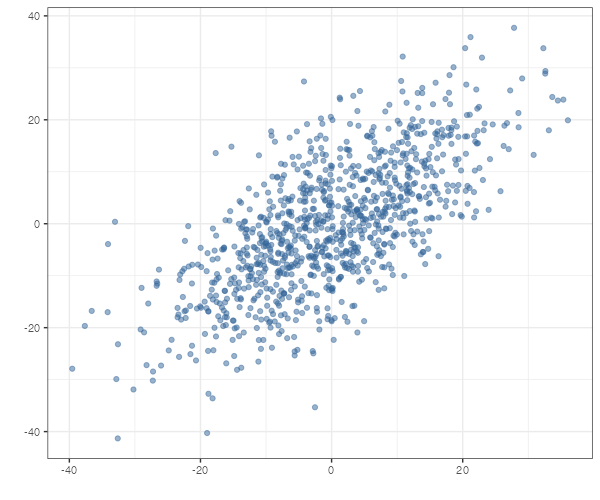
2つの量的変数をx軸、y軸にして点(x,y)を座標平面にプロットするグラフを散布図(scatter plot)といいます。
1つしか軸がないときに値をプロットすると重なって見にくくなってしまいましたが、2つ軸があれば大丈夫ですね。もし重なりが多くて見にくくなるときは、点を半透明にしてやると多少見やすくなります。
それでも見にくいときは、一方を要約値にしてやればいいです。例えば、USJに遊びに来た人について、横軸に来場日、縦軸に来場者が持ってきた現金の金額をプロットすることを想像してみましょう。おそらく来場者が多すぎて、普通にプロットすると重なってよく分からなくなりますね。そこで、要約値をプロットしてやれば見やすくなります。下のグラフでは箱ひげ図と平均値(赤)を重ねて描きました。
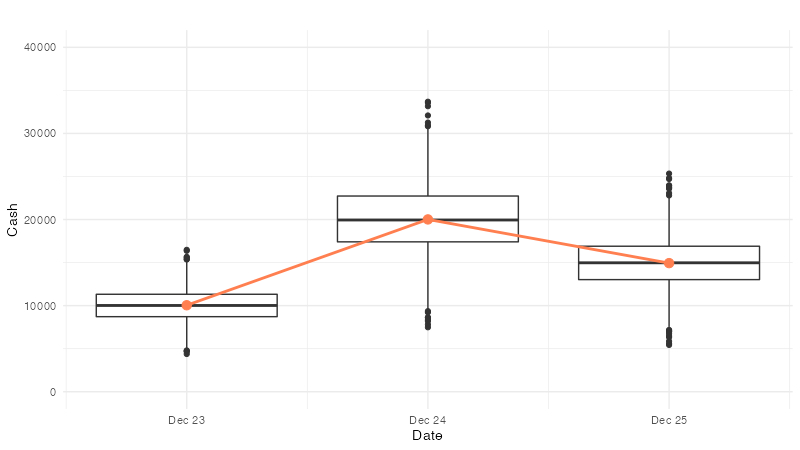
この例のように、時間的な変化を示す場合に限っては、折れ線でつないでもいいです。
量的変数と質的変数が1つずつ
質的変数の水準別に量的変数の分布を示します。 例えば、生徒の血液型と数学の点数を表すグラフを考えましょう。
1つ目の軸に血液型を割り当てて、2つ目の軸に数学の点数を割り当てます。人数が少なければあまり重なりも気にならずにプロットできますね。人数が多ければ箱ヒゲ図で要約値をプロットするか、ヒストグラム(あるいは密度プロット)で示すとスッキリします。
下のグラフは、バイオリンプロット(violin plot)と呼ばれるもので、密度プロットを両側対称にしたものです。

2つの質的変数を示す
2つの質的変数を2つの軸で表すことはできません。質的変数はプロットの重なりが避けられないからです。3つ目の軸を高さにすることは極力避ける、と説明しましたね。色などを使って表せないか考えてみましょう(下は再掲です)。
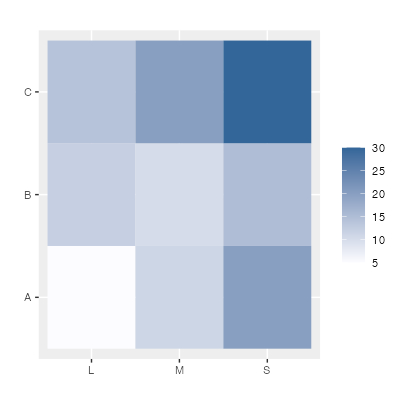
おわりに
- 質的変数を示すには、もう1つ軸が必要。
- 量的変数をそのままプロットして見にくくなるようなら、要約値系(箱ひげ図)かヒストグラム系(密度プロットも含む)。
- 次回:高校生のためのデータ分析入門 (6):データ分析の大黒柱、正規分布 - ねこすたっと
*1:点を打つこと










 療法食 猫用 ストルバイトケア チキンテイスト 400g×4袋")