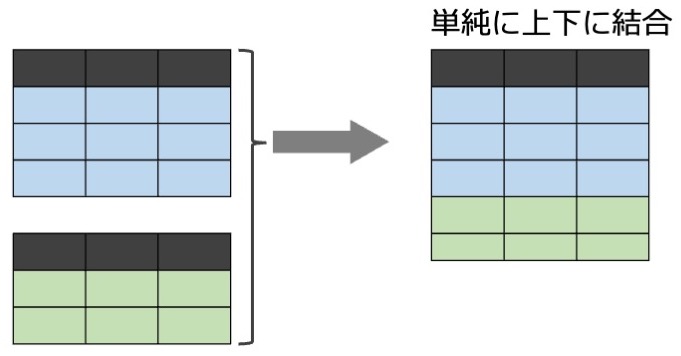
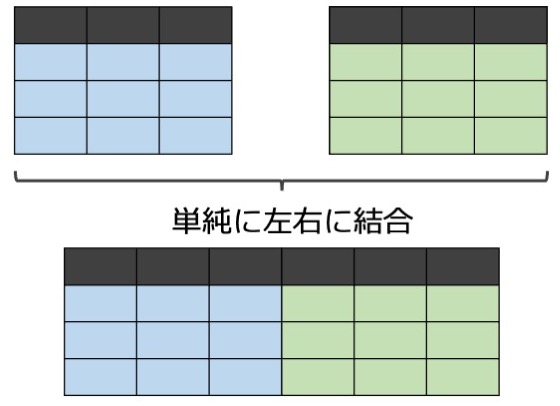
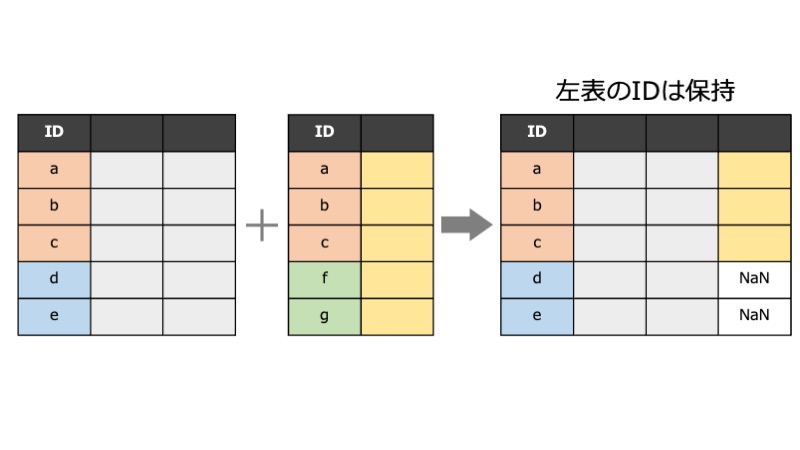
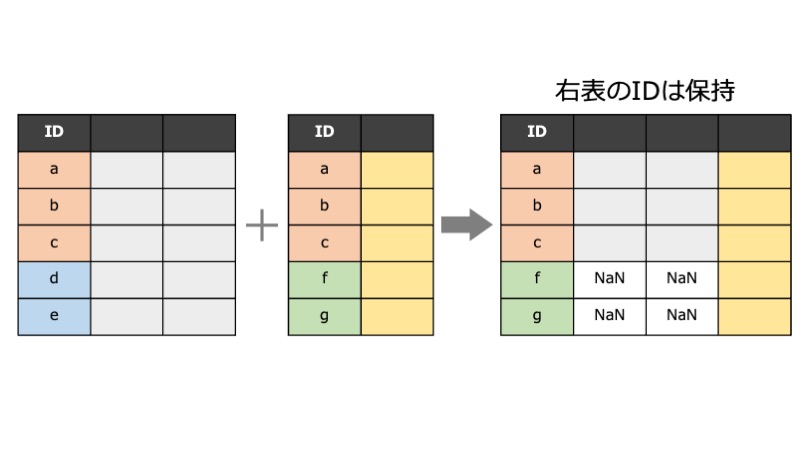
Rもたいして使いこなせてないのにPythonの勉強を始めてみました。色々と素晴らしいチュートリアルはありそうですが、目移りしてしまうので公式チュートリアルを拾い読みしていきます。
NumPyのあとPandasチートシート(PDF)を中心に読んできましたが、今回で最後です。
前回:
最終回は「データの要約と可視化」です。Pandas公式チュートリアル拾い読みの初回で紹介した、irisデータを例に使います。
import pandas as pd df = pd.read_csv("iris.csv")
データの形状を調べる
.shape()メソッドでdfの形状を表示します。
df.shape # 出力: (150, 5)
150行5列のデータであることがわかります。
行数を知りたいときは、len()関数を使うこともできます。
len(df) # 出力: 150
連続変数の要約統計量を計算する
dfに含まれる連続変数の要約値をまとめて調べたいときは.describe()というメソッドを使います。
df.describe() # 出力: sepal.length sepal.width petal.length petal.width count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.057333 3.758000 1.199333 std 0.828066 0.435866 1.765298 0.762238 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000
個々の統計量を得たい場合は次のメソッドを使います。
.sum():合計.count():観測個数.median():中央値.quantile([0.25,0.75]):四分位範囲.min():最小値.max():最大値.mean()平均.var():分散.std():標準偏差
カテゴリー変数を要約する
カテゴリー変数に対して.nunique()メソッドを適用すれば、カテゴリー数がわかります。
df["variety"].nunique() # 出力: 3
個々のカテゴリーに含まれる観察数を求めたい場合は、.value_counts()を使います。
df["variety"].value_counts() # 出力: Setosa 50 Versicolor 50 Virginica 50 Name: variety, dtype: int64
グループごとに要約する
例えば治療群など、ある変数のカテゴリー別に要約したいときには、.groupby()メソッドを使ってデータ内のグループ構造を指定します。
グループ分けに使う変数はbyで指定します(インデックス名を使って分けたいときはlevelを使うみたいです)。
df_grouped = df.groupby(by="variety")
各グループ毎に要約する
グループ化されたデータに.describe()メソッドを使うと、各グループ毎の要約が返されます。
df_grouped.describe() # 出力: sepal.length (略) count mean std min 25% 50% 75% max ~ variety Setosa 50.0 5.006 0.352490 4.3 4.800 5.0 5.2 5.8 ~ Versicolor 50.0 5.936 0.516171 4.9 5.600 5.9 6.3 7.0 ~ Virginica 50.0 6.588 0.635880 4.9 6.225 6.5 6.9 7.9 ~
各グループの観察数を調べる
グループ化されたデータに.size()メソッドを使うと、各グループのデータ数が返されます。
df_grouped.size() # 出力: variety Setosa 50 Versicolor 50 Virginica 50 dtype: int64
グループ内の順位を返す
.rank()メソッドを使うと、それぞれのデータの各グループ内での順位が返されます。
主な引数は、以下のとおり。
method:同じ値(タイ)の扱い方を指定します。デフォルトはaverageで、タイには平均順位が割り振られます。ascending:デフォルトはTrueで、小さい値に小さい順位が振られます。pct:Trueにすると0-1の範囲にスケーリングされます。
df_grouped.rank(method="average") # 出力: sepal.length sepal.width petal.length petal.width 0 32.5 31.5 18.0 20.0 1 18.5 5.5 18.0 20.0 2 10.5 15.0 8.0 20.0 3 7.5 10.5 31.0 20.0 4 24.5 36.0 18.0 20.0 .. ... ... ... ... 145 31.0 27.5 17.5 40.5 146 16.5 3.5 8.0 19.0 147 26.5 27.5 17.5 24.5 148 12.5 46.5 21.5 40.5 149 7.0 27.5 13.0 11.0 [150 rows x 4 columns]
プロットする
チートシートの扱いはかなり小さく、本格的なグラフ作成をするには(他のライブラリを含め)もう少しじっくりと勉強する必要がありそうです。 ここではチートシートに載っていたヒストグラムと散布図だけにとどめておきます。
.plot()メソッドの中に、グラフの種類を指定すればひとまず描けます。ヒストグラムならkind="hist"だそうです。
df["sepal.length"].plot(kind="hist")
.plotの後に.hist()を繋げても描けるようです。
df["sepal.length"].plot.hist()

散布図はx軸に持ってくる変数とy軸に持ってくる変数を指定する必要があります。
df.plot.scatter(x="sepal.length",y="sepal.width")

おわりに
今回学んだこと:
- 代表的な要約統計量を計算する
- グループ毎に計算する
- 非常に簡単なプロット
チュートリアルは読んだけど取り上げなかったもの:
- グループ毎に累積和などを計算する方法(
.cumsum()など) - グループ毎に決まった数だけずらす方法(
.shift())
次回:未定