ロジスティック回帰モデルなどから予測されるアウトカム発生確率(=予測確率)をグラフで可視化したいとします。 1つの変数に対して予測確率がどのように変化していくかを示したければ、折れ線グラフにしたり、変数をカテゴリー化して棒グラフで表したりすることができます。
2つの変数に対して予測確率がどのようになるかを示すときも、変数をカテゴリー化して3D棒グラフにする方法が思いつきますが、3D棒グラフは重なりがあったり高さを比べにくかったりするので推奨されません。
そこで、該当するカテゴリーの予測確率を「棒の高さ」ではなく「色の濃淡」で表すヒートマップ(heat map)と呼ばれる方法があります。
ここでは、予測確率をggplot2パッケージのgeom_tile関数を使ってヒートマップとして表してみます。
モデルの当てはめ
使用するパッケージとデータを準備する
gtsummaryパッケージのtrialデータを使います。
library(tidyverse) data(trial, package="gtsummary")
これは仮想の臨床試験データで、実際のデータは次のような感じです。
> trial %>% glimpse Rows: 200 Columns: 8 $ trt <chr> "Drug A", "Drug B", "Drug A", "Drug A", "Drug A", "Drug B", "D… $ age <dbl> 23, 9, 31, NA, 51, 39, 37, 32, 31, 34, 42, 63, 54, 21, 48, 71,… $ marker <dbl> 0.160, 1.107, 0.277, 2.067, 2.767, 0.613, 0.354, 1.739, 0.144,… $ stage <fct> T1, T2, T1, T3, T4, T4, T1, T1, T1, T3, T1, T3, T4, T4, T1, T4… $ grade <fct> II, I, II, III, III, I, II, I, II, I, III, I, III, I, I, III, … $ response <int> 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0,… $ death <int> 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0, 0,… $ ttdeath <dbl> 24.00, 24.00, 24.00, 17.64, 16.43, 15.64, 24.00, 18.43, 24.00,…
ロジスティック回帰モデルを当てはめる
deathをアウトカム変数、ageとmarkerを説明変数としてロジスティック回帰モデルを当てはめます(ageとmarkerはともに連続変数だったので選んだだけ)。age*markerはage + marker + age:markerと同じで、2つの変数の主効果と交互作用を含めることを意味します。
fit <- glm(death ~ age*marker, data = trial, family = binomial(link = "logit"))
今回はヒートマップ作成が目的なので、モデルの中身は確認しません。
作図用データセットの作成
仮想的に説明変数を作成する
ageは最小値6歳, 最大値83歳なので、10歳から80歳まで10歳刻みの8つのカテゴリーにします。
また、markerは最小値0.0030, 最大値3.879なので、0.5から3.5まで0.5刻みの7つのカテゴリーにします。
この8×7=56カテゴリーのそれぞれについて、モデルに基づいた予測確率を計算し、その予測確率に色を変えてヒートマップにします。
まずは上記のとおり、2つの説明変数を作成します(_imgはimaginaryの意味)。
age_img <- seq(from=10, to=80, by=10) marker_img <- seq(from=0.5, to=3.5, by=0.5)
expand.grid関数を使って全ての組み合わせを含むデータフレームを作る
age_img, marker_imgの全ての組み合わせを含むデータフレームを作りたいんですが、手書きだとかなり面倒です。そこでexpand.grid関数を使います。試しに2つの仮想説明変数を入れてみると、
> expand.grid(age_img, marker_img) Var1 Var2 1 10 0.5 2 20 0.5 3 30 0.5 4 40 0.5 5 50 0.5 6 60 0.5 7 70 0.5 8 80 0.5 9 10 1.0 10 20 1.0 (省略) 54 60 3.5 55 70 3.5 56 80 3.5
となり、56カテゴリー全てのパターンが含まれていることが分かります。
後で当てはめたモデルで予測確率を計算できるように、変数の名前を直しておきましょう。
data_img <- as.data.frame(expand.grid(age_img, marker_img)) %>% rename(age = Var1, marker = Var2)
predict関数を使って予測確率を計算する
predict関数には次の引数を指定してあげます。
- 当てはめたモデル。ここでは
fit - 予測確率を計算したい新しいデータセット。ここでは
data_img - 出力したいもの。予測確率(0〜1)を出力したい場合は
type="response"、線形予測子(-∞〜+∞)を出力したい場合はtype="link"を指定。
計算されたものをpredという名前でデータフレームに付け加えます。
data_img$pred <- predict(fit, data_img, type="response")
出来上がった作図用データセットは次のとおり。
> data_img age marker pred 1 10 0.5 0.3782241 2 20 0.5 0.4202963 3 30 0.5 0.4635594 4 40 0.5 0.5073781 5 50 0.5 0.5510838 6 60 0.5 0.5940146 7 70 0.5 0.6355549 8 80 0.5 0.6751691 9 10 1.0 0.4885478 10 20 1.0 0.4997700 (以下略)
作図
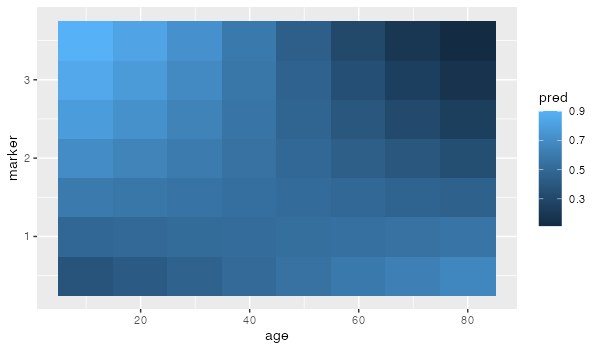
geom_tile関数を使ってヒートマップを描く
geom_tile関数を使います。
q <- ggplot(data=data_img, aes(x = age, y = marker, fill = pred)) + geom_tile() print(q)
グラデーションの色を変える
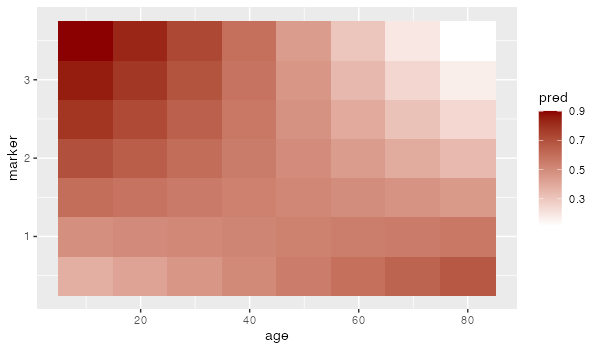
レイヤーとしてscale_fill_gradient( )を重ねることで色を変えることができます。
低値の色(low)をwhite、高値の色(high)をdarkredに指定してみます。
q + scale_fill_gradient(low = "white", high = "darkred")
中間にもう一色追加したい場合はscale_fill_gradient2( )を使います。正負両方向に分布しているデータなど、真ん中に基準点(例えば0)がある場合に有用です。今回は低値(low)をdarkgreen, 高値(high)をdarkred、基準点(midpoint)を0.5として基準点の色(mid)をwhiteにしてみます。
q + scale_fill_gradient2(low="darkgreen", mid="white", high = "darkred", midpoint = 0.5)

おわりに
- ヒートマップ自体は古くからある手法のようです( ヒートマップ - Wikipedia )。
- 猫が毎朝ルンバとジャレるので掃除できていない範囲があります。