列、つまり変数に対する操作のまとめ。
ここでもsurvivalパッケージのpbcデータセット(の一部)を例として使う。
> library(survival) > set.seed(1234) > data(pbc) > d <- pbc[1:6,1:6] > d[6,2:6] <- NA > d id time status trt age sex 1 1 400 2 1 58.76523 f 2 2 4500 0 1 56.44627 f 3 3 1012 2 1 70.07255 m 4 4 1925 2 1 54.74059 f 5 5 1504 1 2 38.10541 f 6 6 NA NA NA NA <NA>
tidyverseパッケージを読み込んでおく。
library(tidyverse)
select( )を使って変数を指定して抽出する
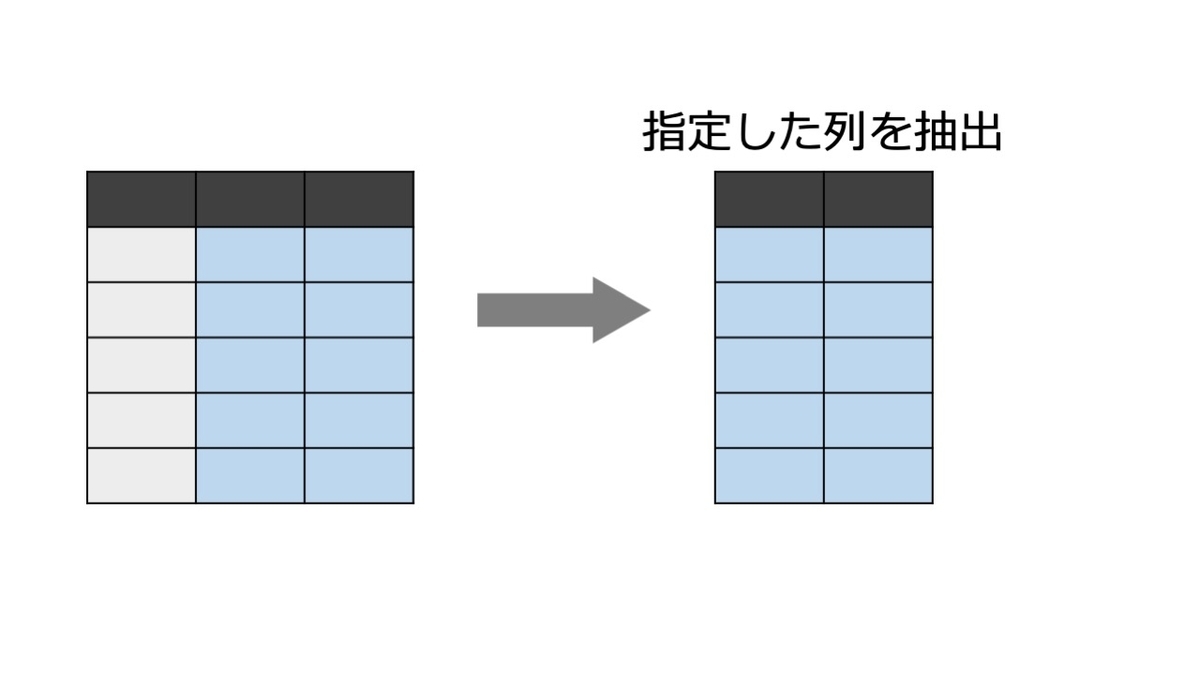
残したい変数名を指定する。
> d %>% select(id, age, sex) id age sex 1 1 58.76523 f 2 2 56.44627 f 3 3 70.07255 m 4 4 54.74059 f 5 5 38.10541 f 6 6 NA <NA>
除外したい変数はマイナスをつける(結果省略)。
d %>% select(-age, -sex)
変数の冒頭の文字列をもとに指定することも可能。
> d %>% select(starts_with("t")) time trt 1 400 1 2 4500 1 3 1012 1 4 1925 1 5 1504 2 6 NA NA
tから始まるtimeとtrtが抽出された。
変数名による指定方法は他にもあるので下を参照のこと。
starts_with():変数名が〜で始まるends_with():変数名が〜で終わるcontains():変数目に〜を含む
後々使いやすいように変数名を決めておくことが重要。
rename( )で変数名を変更する
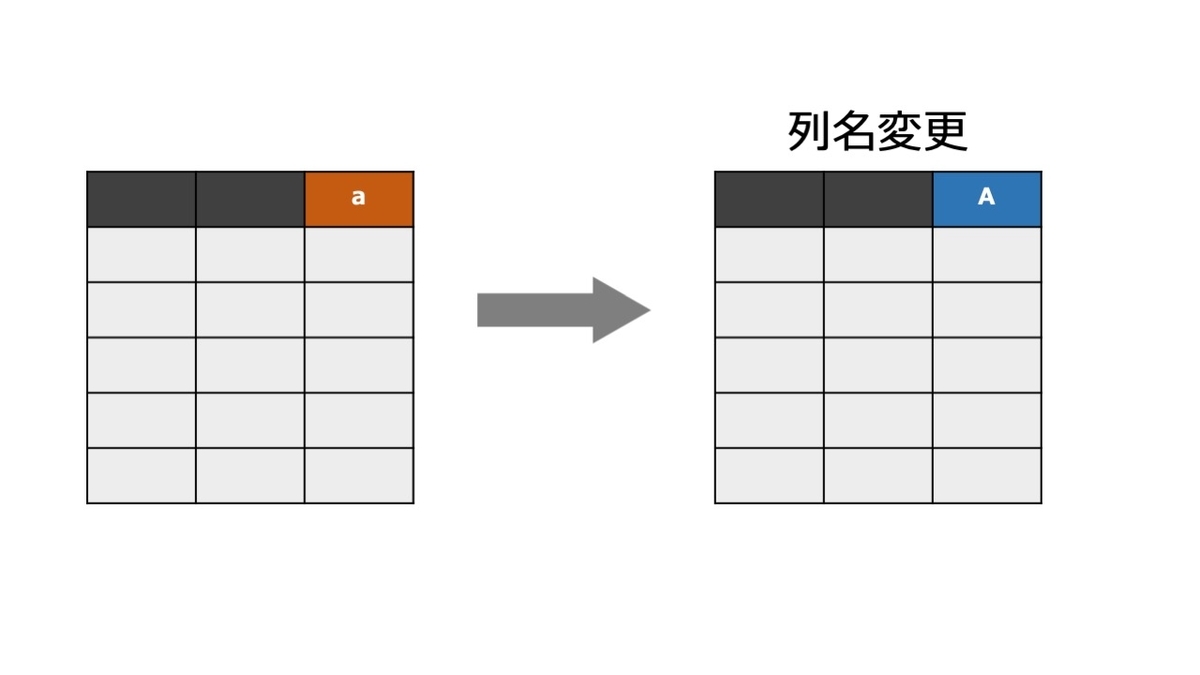
「変更後の名前=元の名前」のように指定する。
> d %>% rename(gender=sex) id time status trt age gender 1 1 400 2 1 58.76523 f 2 2 4500 0 1 56.44627 f 3 3 1012 2 1 70.07255 m 4 4 1925 2 1 54.74059 f 5 5 1504 1 2 38.10541 f 6 6 NA NA NA NA <NA>
実はselect( )を用いる段階で改名しておくこともできる。
d %>% select(id, age, gender=sex)
もし、他のtidyverse系関数が使えるのにselect( )だけエラーになるときは、MASSパッケージ内の同名の関数とバッティングしている可能性があるので、dplyr::select()とパッケージを明示すると解決するかも。
mutate( )で新しく変数を作成する
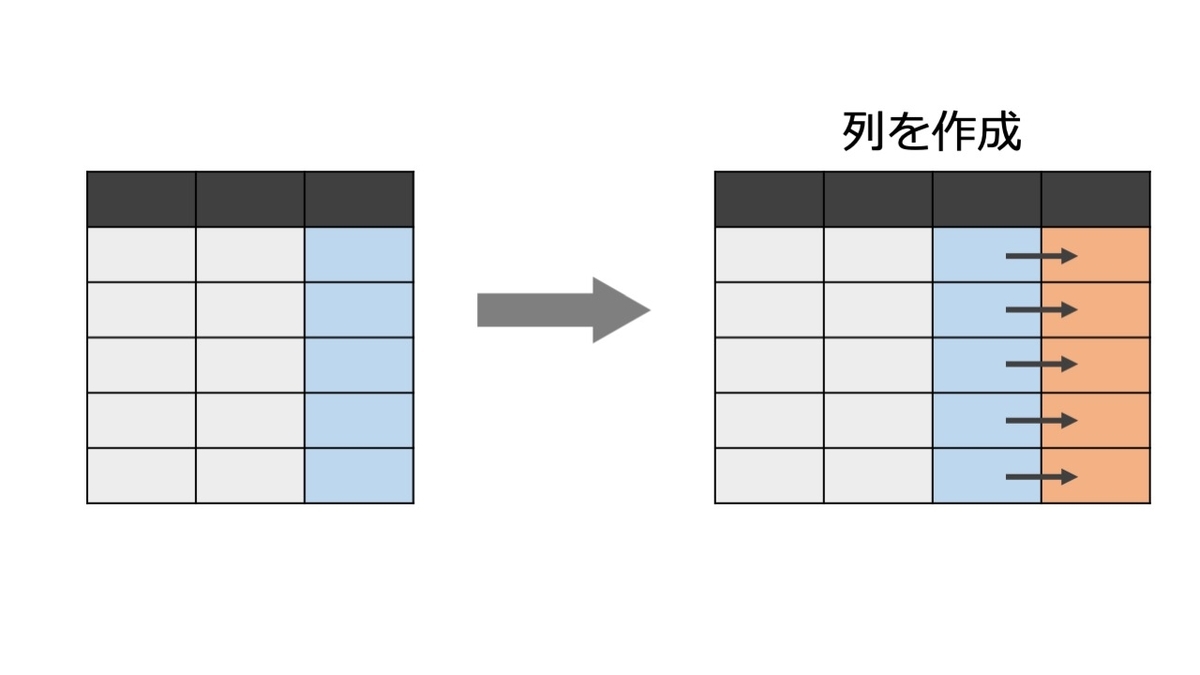
ここでは要約と違い、各行に対応する値を持つ変数を作成する。
(つまり変数ベクトルの長さは不変)
(多分)日単位のtimeを365.25で割って年単位に変換した変数time_yを作成する。
> d %>% mutate(time_y=time/365.25) id time status trt age sex time_y 1 1 400 2 1 58.76523 f 1.095140 2 2 4500 0 1 56.44627 f 12.320329 3 3 1012 2 1 70.07255 m 2.770705 4 4 1925 2 1 54.74059 f 5.270363 5 5 1504 1 2 38.10541 f 4.117728 6 6 NA NA NA NA <NA> NA
単純な演算のほか、条件分岐で値を決めることもできる。
if_else()は、条件に合致したときに返す値、合致しなかったときに返す値を指定する。
> d %>% mutate(trt_AB = if_else(trt==1, "A", "B")) id time status trt age sex trt_AB 1 1 400 2 1 58.76523 f A 2 2 4500 0 1 56.44627 f A 3 3 1012 2 1 70.07255 m A 4 4 1925 2 1 54.74059 f A 5 5 1504 1 2 38.10541 f B 6 6 NA NA NA NA <NA> <NA>
3つ以上のカテゴリーを持たせるときはif_else( )よりもcase_when( )が便利。
これは「条件 ~ それを満たす時の値」というように指定していく。
ただし条件は書いた順に優先されるので注意。
d %>% mutate(age_cat = case_when(age>=60 ~ "older", age<60 ~ "middle", age<50 ~ "young"))
id time status trt age sex age_cat 1 1 400 2 1 58.76523 f middle 2 2 4500 0 1 56.44627 f middle 3 3 1012 2 1 70.07255 m older 4 4 1925 2 1 54.74059 f middle 5 5 1504 1 2 38.10541 f middle 6 6 NA NA NA NA <NA> <NA>
例えば症例5では、3番目のage<50 ~ "young"よりも2番目のage<60 ~ "middle"が優先されてしまったため、意図したのと異なるカテゴリーが付与されてしまった。
正しくは以下のとおり(結果割愛)。
d %>% mutate(age_cat = case_when(age<50 ~ "young", age<60 ~ "middle", age>=60 ~ "older"))
おわりに
- mutateを使うときの条件の優先順位を間違わないように。
参考資料
- わかりやすい前田和寛(@kazutan)先生のページ。
- 本家ページ