データを要約する操作のまとめ。
新しい変数を作るのと違い、要約された後は元の変数よりもベクトルの長さが短くなる。
ここでもsurvivalパッケージのpbcデータセット(の一部)を例として使う。
> library(survival) > set.seed(1234) > data(pbc) > d <- pbc[1:6,1:6] > d[6,2:6] <- NA > d id time status trt age sex 1 1 400 2 1 58.76523 f 2 2 4500 0 1 56.44627 f 3 3 1012 2 1 70.07255 m 4 4 1925 2 1 54.74059 f 5 5 1504 1 2 38.10541 f 6 6 NA NA NA NA <NA>
tidyverseパッケージを読み込んでおく。
library(tidyverse)
summarise( )で要約する
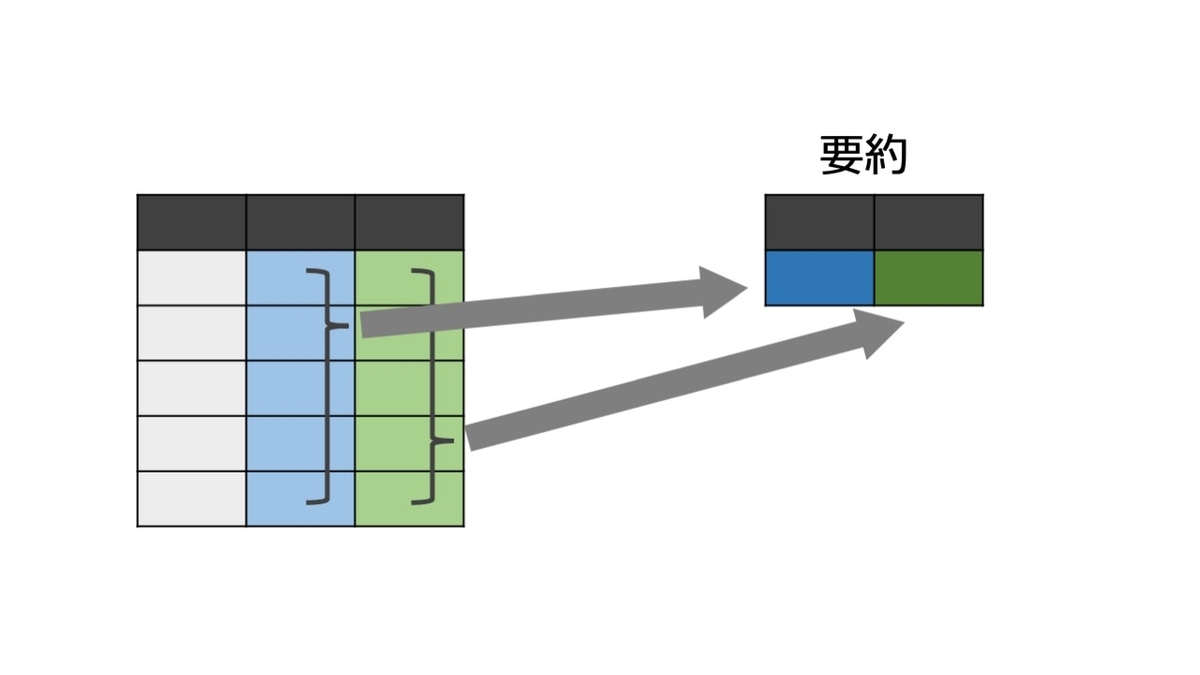
以下、よく使われる要約関数。
n():観察値(行)の数を数える(カッコ内不要)n_distinct():カッコの中の変数で、固有な観測値の数(値が何種類あるか)sum():合計sum(!is.na()):欠測の個数mean(),sd():平均値, 標準偏差median(),IQR(),quantile():中央値, 四分位範囲, パーセンタイルmin(),max():最小値, 最大値first(),last():最初の値, 最後の値
欠測を含んでいると要約できないので、まずdrop_na()で欠測を取り除いてから平均を求める。
→ drop_na( )とすると、関係ない変数に欠測があっても除去されてしまう。mean( )の中にNAを除去(remove)するための引数na.rm=TRUEを指定すればよい。
> d %>% summarise(mean_age = mean(age, na.rm=TRUE)) mean_age 1 55.62601
group_by( )でグループ別に要約する
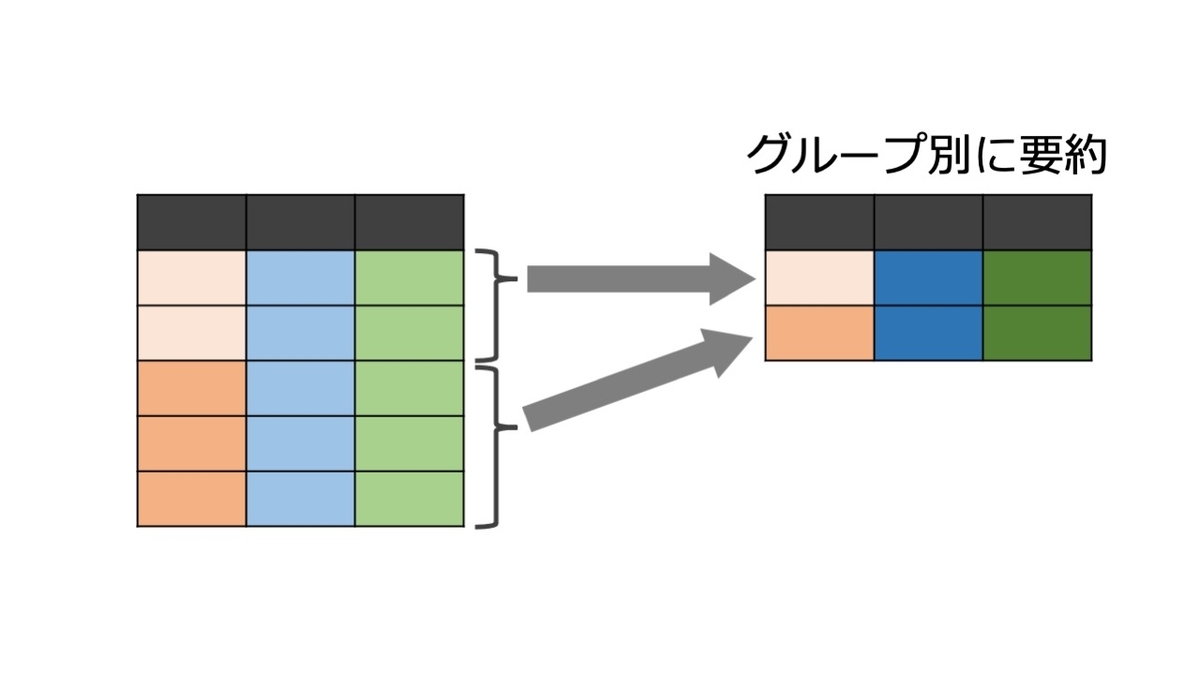
どの変数で群分け(層別化)して要約するのかをgroup_by()で指定する。
d %>% group_by(sex) %>% summarise(mean_age = mean(age, na.rm=TRUE))
# A tibble: 3 × 2 sex mean_age <fct> <dbl> 1 m 70.1 2 f 52.0 3 NA NaN
おわりに
- ここらへんからtidyverseの便利さが一層実感できます。
- 日の出が遅くなってきたからか、朝に窓を開けろとネコに起こされることがなくなってきました。
- 欠測がある場合の要約について修正しました(2022-09-10)
参考資料
- わかりやすい前田和寛(@kazutan)先生のページ。
- 本家ページ