Rもたいして使いこなせてないのにPythonの勉強を始めてみました。色々と素晴らしいチュートリアルはありそうですが、目移りしてしまうので公式チュートリアルを拾い読みしていきます。
NumPyのあとPandasチートシート(PDF)を中心に読んできましたが、そろそろ終盤です。
前回:
今回はデータの結合です。Pandasライブラリを読み込んでおきます。
import pandas as pd
単純に結合する
pd.concate()という関数を使って結合します。引数としてaxis=0とすれば上下方向に、axis=1とすれば左右方向に結合します(デフォルトはaxis=0)。
上下に結合する
模式的に描くと次のような感じです。
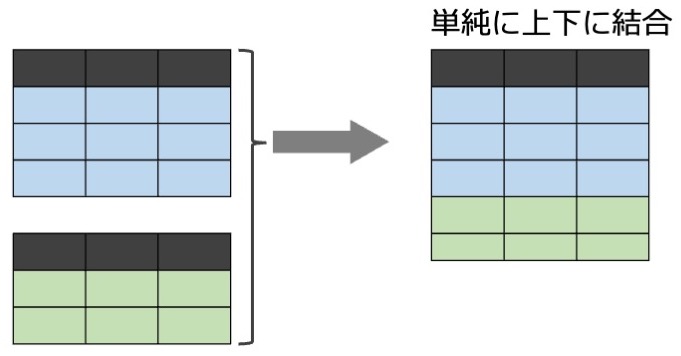
次の2つのサンプルデータ(df1, df2)を上下に結合してみます。2つのdfでは、
- 変数の並び順が異なっている
- 重複データが含まれている
となるようにしてみました。
df1 = pd.DataFrame(
{"patient":["A","B","C"],
"time1":[10,20,30],
"time2":[40,50,60]},
)
df2 = pd.DataFrame(
{"time2":[40,25,35],
"patient":["A","E","F"],
"time1":[10,55,65]},
)
pd.concat([df1,df2],axis=0) # 出力: patient time1 time2 0 A 10 40 1 B 20 50 2 C 30 60 0 A 10 40 1 E 55 25 2 F 65 35
列の順序が異なっていても列名が揃うように結合してくれています。また、単純に結合するだけなので重複は除かれていません。
左右に結合する
模式的に描くと次のような感じです。
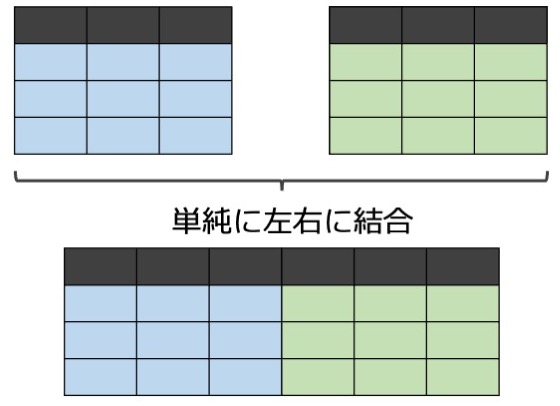
今度は次の2つのサンプルデータ(df1, df3)を左右に結合してみます。2つのdfではpatientの並び順が異なっています。
df1 = pd.DataFrame(
{"patient":["A","B","C"],
"time1":[10,20,30],
"time2":[40,50,60]},
)
df3 = pd.DataFrame(
{"patient":["C","B","A"],
"time3":[15,25,35],
"time4":[45,55,65]},
)
pd.concat()でaxis=1を指定します。
pd.concat([df1,df3],axis=1) # 出力: patient time1 time2 patient time3 time4 0 A 10 40 C 15 45 1 B 20 50 B 25 55 2 C 30 60 A 35 65
並び順はそのままで結合されています。縦方向のときは列名を元にして対応が決められますが、横方向のときはどれが観測単位を識別する変数か分からないので勝手に揃えてはくれません。
次のようにpatientをインデックス名に指定すれば、
df1_new = df1.set_index("patient") df3_new = df3.set_index("patient")
pd.concat([df1_new,df3_new],axis=1) # 出力: time1 time2 time3 time4 patient A 10 40 35 65 B 20 50 25 55 C 30 60 15 45
上手く揃えてくれました。でも、このように揃えて結合したいのであれば、次に紹介する方法を使う方が良さそうです。
キーで紐付けて結合する
キーで紐付けして結合する場合は、pd.merge()という関数を使います。指定する主な引数は、
how:どの行を残すのか(left,right,inner,outer)を指定しますon:紐付けに使うキーを指定します
左側のdfの行を残す
how=leftとすると、左側(1つ目に指定したdf)に含まれる対象者のみ残ります。右側(2つ目に指定したdf)にデータがない箇所はNaNになります。
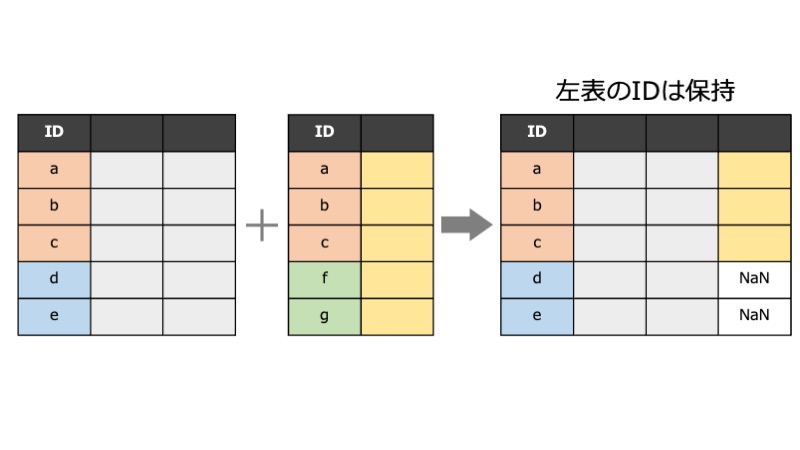
試しに次の2つのdfを結合してみます。
df1 = pd.DataFrame(
{"patient":["A","B","C"],
"time1":[10,20,30],
"time2":[40,50,60]},
)
df2 = pd.DataFrame(
{"time2":[40,25,35],
"patient":["A","E","F"],
"time1":[10,55,65]},
)
df1が左側、df2が右側として、patientを紐付けキーにして結合します。
pd.merge(df1, df2, how="left", on="patient") # 出力: patient time1_x time2_x time2_y time1_y 0 A 10 40 40.0 10.0 1 B 20 50 NaN NaN 2 C 30 60 NaN NaN
右側のdfに含まれていない"B", "C"についてはデータが追加されずNaNとなっています。
また、左右で同じ列名がある場合、結合すると列名が重複してしまうので、左側のdfの列名には_x、右側のdfの列名には_yの接尾辞が付与されます。
右側のdfの行を残す
how=rightとすると、右側(2つ目に指定したdf)に含まれる対象者のみ残ります。
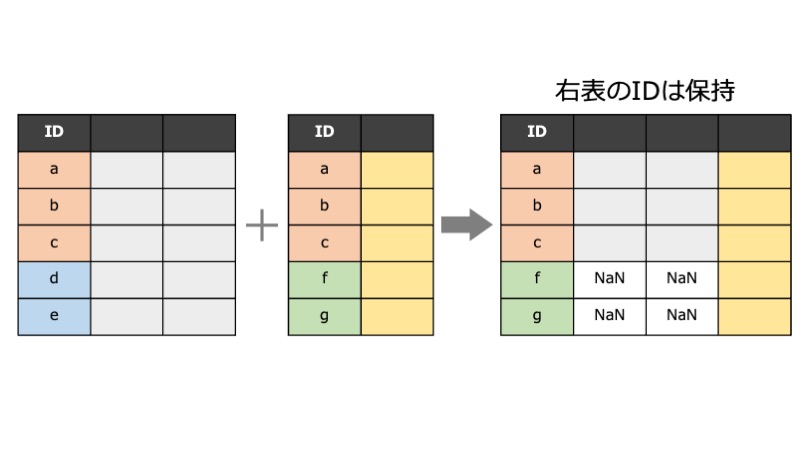
指定するdfの順序を入れ替えて、how=leftとしても一緒なので、あまり使う機会がありません。
どちらのdfにも含まれる行を残す
how=innerとすると、左右どちらのdfにも含まれている対象者(積集合)が残ります。
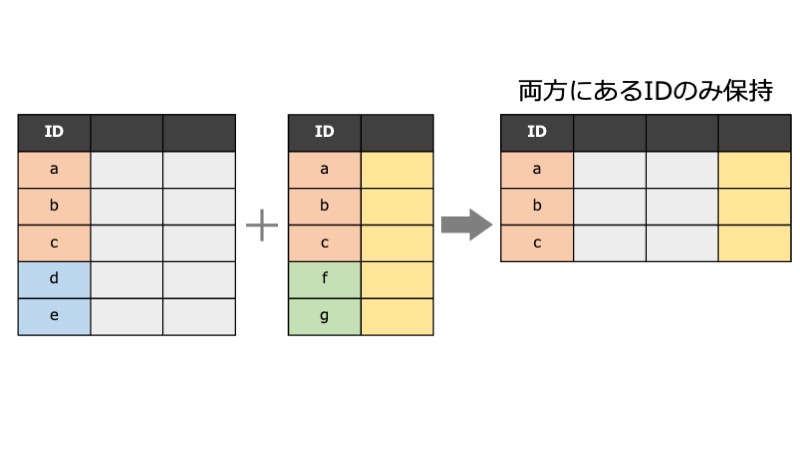
全ての行を残す
how=outerとすると、どちらかのdfに含まれている対象者(和集合)が残ります。
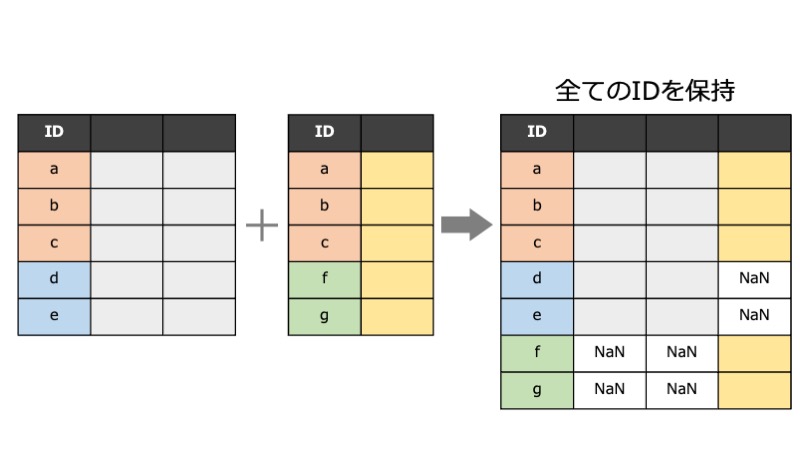
おわりに
今回学んだこと:
- 2つのデータをキーで紐つけて結合する方法
チュートリアルは読んだけど取り上げなかったもの:
- 今回もありません(チュートリアルを読む量が少ないだけ)。
次回: