臨床現場では、対象者の年齢や症状、検査値などをもとにして計算される「何とかスコア」が使われることがよくあると思います。 臨床研究でも、既に収集された項目からcomposite scoreを計算し、変数に追加したいことはよくあります。 今回はtidyverseパッケージを使って、この操作を簡単に行う方法をまとめてみます。
以前、tidyverseパッケージを使ってデータ行に対する操作をまとめたことがありますが、今回扱う内容はあくまで行単位で列に関する操作を行うものなので別物です。
- 必要なパッケージとデータの準備
- rowwiseを使わずに既存の変数から新しい変数を作成する
- rowwiseを使って既存の変数から新しい変数を作成する
- c_across( )を使って使用する列を条件式で指定する
- おわりに
- 参考資料
必要なパッケージとデータの準備
まずはtidyverseパッケージを読み込みます。
library(tidyverse)
今回もggplotでお馴染みのdiamondsデータを使います。diamondsデータに馴染みがなくても、データセットであることがすぐにわかるように、データ名はdataに変更しておきます。
> data <- diamonds > data # A tibble: 53,940 × 10 carat cut color clarity depth table price x y z <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl> 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31 4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48 7 0.24 Very Good I VVS1 62.3 57 336 3.95 3.98 2.47 8 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53 9 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49 10 0.23 Very Good H VS1 59.4 61 338 4 4.05 2.39 # … with 53,930 more rows
rowwiseを使わずに既存の変数から新しい変数を作成する
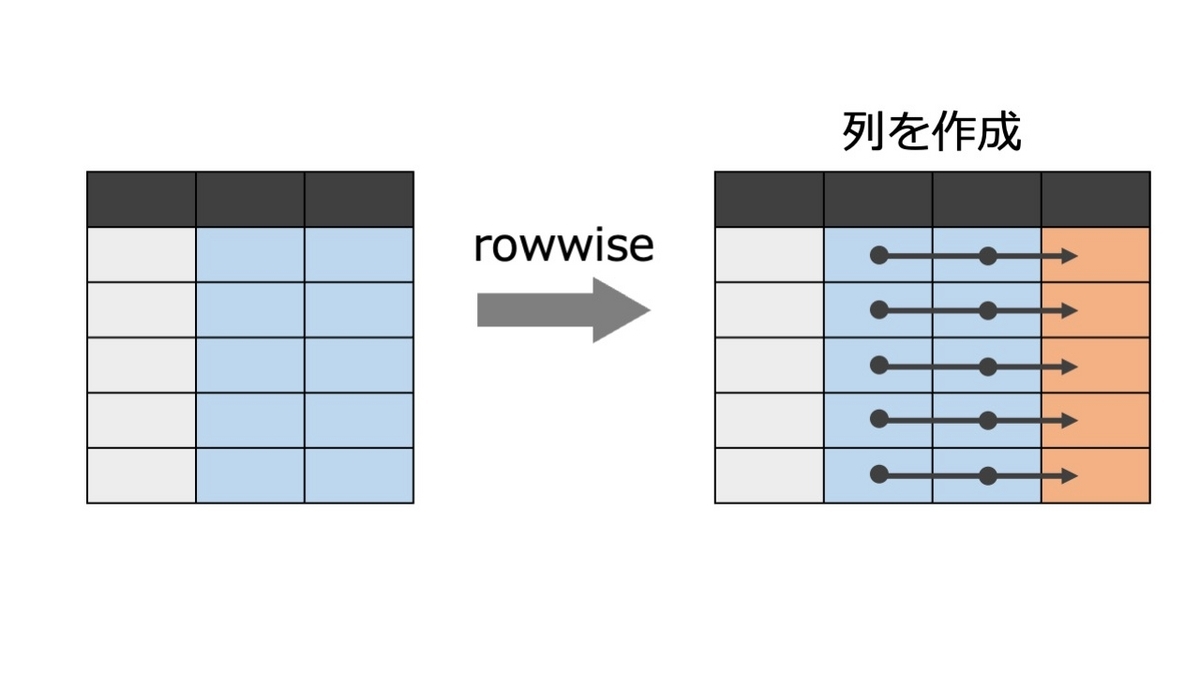
例えば、diamondsデータの変数x, y, zから、それらの合計(x+y+z)を保持するwという変数を追加してみます。やりたいことを模式的に描くと、次のようになります。
diamonds %>% mutate(w = sum(x, y, z))
直感的にはこのように書きたくなるんですが、これを実行すると次のような変数が追加されます。
# A tibble: 53,940 × 11 carat cut color clarity depth table price x y z w <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43 809338. 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31 809338. 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31 809338. 4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63 809338. 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75 809338. 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48 809338. 7 0.24 Very Good I VVS1 62.3 57 336 3.95 3.98 2.47 809338. 8 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53 809338. 9 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49 809338. 10 0.23 Very Good H VS1 59.4 61 338 4 4.05 2.39 809338. # … with 53,930 more rows
さっきのコードでは、xがそれぞれの個体における計測値ではなく、全ての個体の計測値を含んだものとして認識されるからです。なので、w=x+y+zと計算すると、データフレームに含まれる全てのx, y, zが足されてしまうことになります。
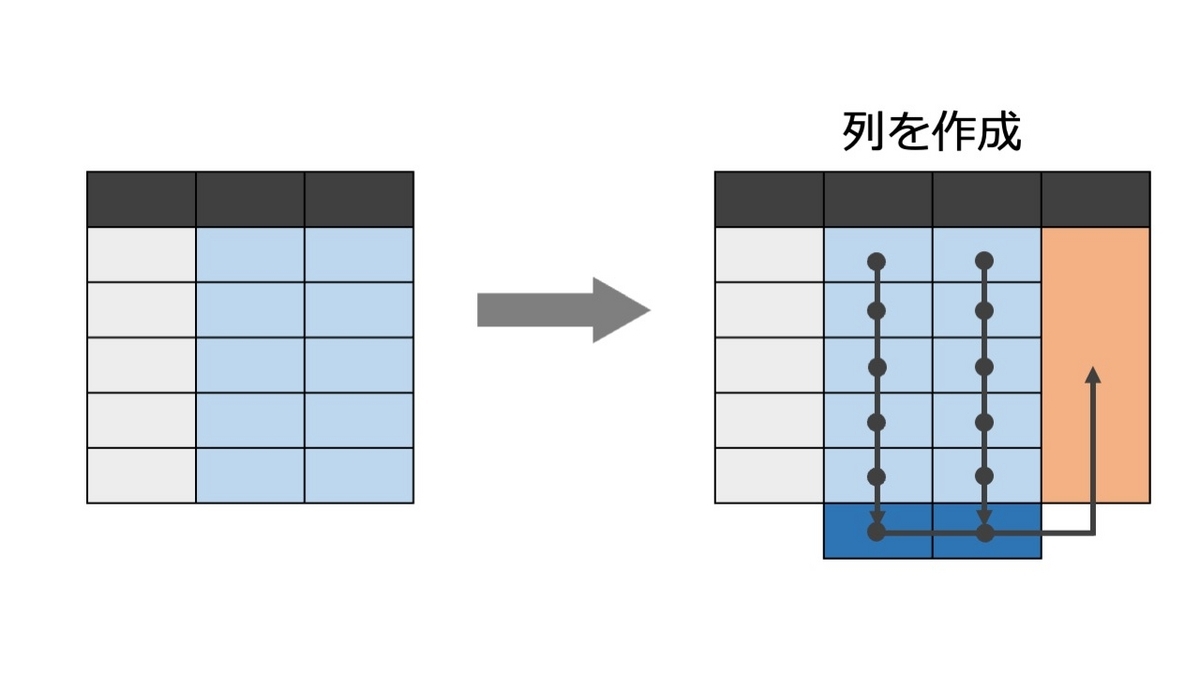
group_byを使う
個々の行毎に計算を行いたいので、行を1つのグループと認識させてからwを作成してみます。
行番号は変数になっていないので、row_number( )として行番号の変数を作成します。他にもrownames_to_column( )でも行番号を変数にできます。
diamonds %>% group_by(row_number()) %>% mutate(w = sum(x, y, z))
# A tibble: 53,940 × 12 # Groups: row_number() [53,940] carat cut color clarity depth table price x y z `row_number()` w <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <int> <dbl> 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43 1 10.4 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31 2 10.0 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31 3 10.4 4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63 4 11.1 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75 5 11.4 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48 6 10.4 7 0.24 Very Good I VVS1 62.3 57 336 3.95 3.98 2.47 7 10.4 8 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53 8 10.7 9 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49 9 10.1 10 0.23 Very Good H VS1 59.4 61 338 4 4.05 2.39 10 10.4 # … with 53,930 more rows
これで思っていた変数wが作成できました。
rowwiseを使って既存の変数から新しい変数を作成する
これをもう少し簡単に実行してくれるのがrowwise( )関数です。文字どおり「行単位(rowwise)」で操作を行うための関数です。 使い方は簡単で、下のようにmutate( )を実行する前にrowwise( )を差し込むだけです。
diamonds %>% rowwise() %>% mutate(w = sum(x, y, z))
# A tibble: 53,940 × 11 # Rowwise: carat cut color clarity depth table price x y z w <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43 10.4 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31 10.0 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31 10.4 4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63 11.1 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75 11.4 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48 10.4 7 0.24 Very Good I VVS1 62.3 57 336 3.95 3.98 2.47 10.4 8 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53 10.7 9 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49 10.1 10 0.23 Very Good H VS1 59.4 61 338 4 4.05 2.39 10.4 # … with 53,930 more rows
これだと行番号を示す余計な変数が作成されなくていいですね。
c_across( )を使って使用する列を条件式で指定する
新しい変数の計算に用いたい変数がたくさんあるときは、全てを書き出すのが面倒です。そんなときはc_across( )*1を使うと便利です。
例えば、数値型(numeric)の変数を全て足し合わせた値をsum_numという名前の変数として追加してみます。
diamonds %>% rowwise() %>% mutate(sum_num = sum(c_across(where(is.numeric))))
条件指定の方法については、前に書いた記事を参考にしてください。
across( )では「複数の列に対して個別に関数を適用する」のに対し、c_acrossでは「複数の列を関数を使って1つの列に統合(combine)する」ための関数です。
結果は次のようになります。
# A tibble: 53,940 × 11 # Rowwise: carat cut color clarity depth table price x y z sum_num <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43 453. 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31 457. 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31 460. 4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63 466. 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75 468. 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48 466. 7 0.24 Very Good I VVS1 62.3 57 336 3.95 3.98 2.47 466. 8 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53 465. 9 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49 473. 10 0.23 Very Good H VS1 59.4 61 338 4 4.05 2.39 469. # … with 53,930 more rows
rowwise( )を書いてないと、全ての数値型変数の値を足し合わせた数値が追加されるだけになることに注意しましょう。
おわりに
- rowwise( )はgroup_by( )の特殊系。こららは単体ではデータに「印」をつけるだけで何もしない。
- 親切心でクーラーをつけっぱなしで外出しますが、ネコたちはクーラーがあまり好きではないようです。
参考資料
- 本家資料(ただし1割も扱えていない)
*1:combine acrossの"c_"でしょうか