性質が類似していると考えることが自然な構造を持つデータをクラスターデータと呼ぶ。
例えば、
- 世帯・学校などの構成員のデータ
- 同一対象から反復して測定されたデータ
はクラスターデータと考えて解析することが多い。
普通は1行=1対象者としてデータを整形するため、この場合は反復測定されたデータは横方向に付け足されることになるが、 1行=1測定として縦長のデータとして扱うこともある。
ここでは、このように縦型データ・横型データを相互に変換する操作を扱う。
例としてマイケルソン・モーリーの実験のデータ(morley)を用いる。
> data(morley) > morley Expt Run Speed 001 1 1 850 002 1 2 740 003 1 3 900 ~~~ 019 1 19 960 020 1 20 960 021 2 1 960 022 2 2 940 ~~~ 098 5 18 800 099 5 19 810 100 5 20 870
このように元々が縦長のデータ。
tidyverseパッケージを読み込んでおく。
library(tidyverse)
pivot_wider( )を使って横長にする

以下の引数を指定:
names_from:新たに作成する変数の名前が格納されている列を指定names_prefix:変数名に接頭辞をつけたいときに指定
values_from:新たに作成する変数の値が格納されている列を指定
d_wide <- morley %>% pivot_wider(names_from="Run", values_from="Speed", names_prefix="run_")
> d_wide # A tibble: 5 x 21 Expt run_1 run_2 run_3 run_4 run_5 ... <int> <int> <int> <int> <int> <int> ... 1 1 850 740 900 1070 930 ... 2 2 960 940 960 940 880 ... 3 3 880 880 880 860 720 ... 4 4 890 810 810 820 800 ... 5 5 890 840 780 810 760 ...
pivot_longer( )を使って縦長にする
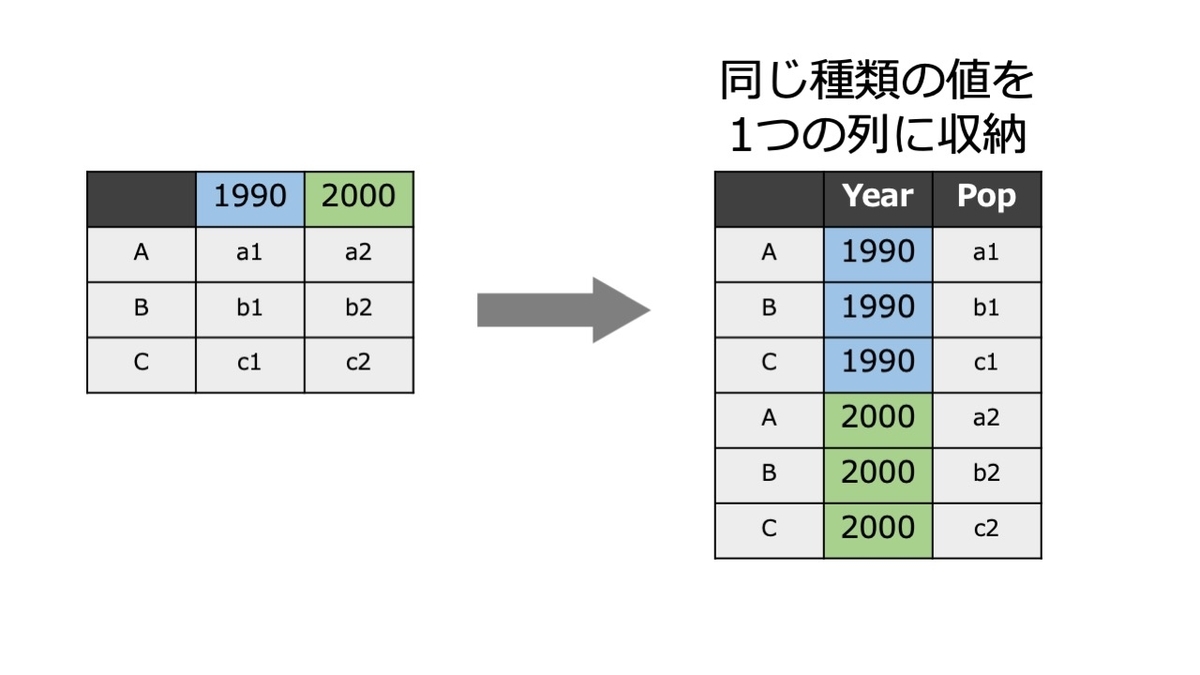
横長を縦長にするときは横に広がった変数のうち、どの範囲を1つの列にまとめるのかをcolsで指定する必要がある。
下のコードではExpt以外を1つの列にまとめるように指定している。
このほかに、以下の引数を指定:
names_to:元々の変数名を格納するための新たな変数の名前を指定values_to:値を格納するための新たな変数の名前を指定
d_long <- d_wide %>% pivot_longer(cols=c(-Expt), names_to="Run", values_to="Speed")
> d_long # A tibble: 100 x 3 Expt Run Speed <int> <chr> <int> 1 1 run_1 850 2 1 run_2 740 3 1 run_3 900 ~~~
おわりに
- これでデータ整形の基本はひととおり終わりです。
参考資料
- わかりやすい前田和寛(@kazutan)先生のページ
- 本家ページ