数学が苦手なうちのJKに、将来必要となるかもしれないデータ分析への抵抗感をなくしてもらう目的で記事を書くことにしました。
回帰モデルは「期待値」と「誤差」でできている
前回、「回帰とは何か」について概要を説明しました。
話の最後に「回帰分析で当てはめる関数(およびそれにまつわる色々な前提条件)のことを回帰モデルと呼ぶ」と言いました。 もう少し掘り下げて説明すると、回帰モデルは「Xが決まったときのYの期待値」と「期待値からの誤差(ズレ)」で構成されます。
例:気温を使って売り上げを予想する
例えば、あなたの部活は秋の文化祭で、毎年おでんの模擬店を出しているとしましょう。 品切れ・売れ残りをなるべく減らしたいのですが、何人分用意したらいいか決めかねています。 幸いなことに、過去の売り上げなどの記録を先輩が残してくれていたので、予想される気温をもとに売り上げ個数を予想することにしました。
- 説明変数(X):最高気温
- 応答変数(Y):おでんの売り上げ数
まずはデータをグラフにしてみました。 気温が低いほど、おでんがよく売れていることがわかります。

天気予報によれば、当日の最高気温は14℃でやや寒いと予想され、回帰直線で14℃のときを見ると100個程度の売り上げがありそうです。 しかし、これはあくまで予測値であり、実際はこれよりも多かったり少なかったりします。 過去のデータでも、最高気温から期待される値(=回帰直線)から、ランダムに上下にずれている、ということが言えそうです。
モデルを3つの数式で表してみる
このことを3つの数式で表してみます。
(1) XによってYの期待値が決まる
左辺 ] は、Yの条件付き期待値(conditional expectation)です。
普通の期待値
] は「観察されたYの平均値」、つまり1つの値ですが、
条件付き期待値
] は
の値によって変わります。
どのように変わるかは、右辺を見れば分かります。例えば、
- X=10℃のとき:
- X=20℃のとき:
といった具合です。
右辺の は切片(intercept)、
は傾き(slope)と呼ぶのは分かりますね。合わせて係数(coefficient)と呼びます*1。
まとめると、1つ目の式は「それぞれのXに対応するYの期待値は、Xの式で決まる」ということを表しています。
(2) 期待値に誤差が加わった値が観察される
次に、2つ目の式です。
左辺 は、実際に観察される値です。 1つ目の式が正しければ、
は
と近い値になるはずですが、XでYが完璧に言い当てられる状況を除いて、かならずズレがあります。
右辺の
*2は、このズレ、つまり誤差を表しています。
回帰直線と観測値のズレは、Xが与えられた状況で考えるので、y軸と平行な方向で測った誤差です。点と直線の距離として、垂線を下ろして測っているわけではないことに注意してください。

(3) 誤差についての仮定
3つ目の式(と言いながら2つ書いてますが)は、誤差に関する仮定(=制約)を表しています。
まず、期待値からのズレの方向、つまり期待値より大きくなるか、小さくなるか、はバランスが取れていないとおかしいですよね。例えば、期待値から上方向にばっかりズレるのであれば、そもそも回帰直線をもう少し上に引いたらいいだけのことです。つまり、誤差の中心は0でなくてはなりません。
次に、ズレの大きさです。期待値から大きく外れることがたまにあってもいいけど、少し外れることよりも頻度が大きいようでは、回帰直線がデータを代表しているとは言えません(直線の周りがスカスカになりますね)。誤差は、中心(=0)に近い方が頻度が高く、中心から離れるほど頻度が低くなるような分布である必要があります。 正規分布を使えば、これらの性質を上手く表せます。
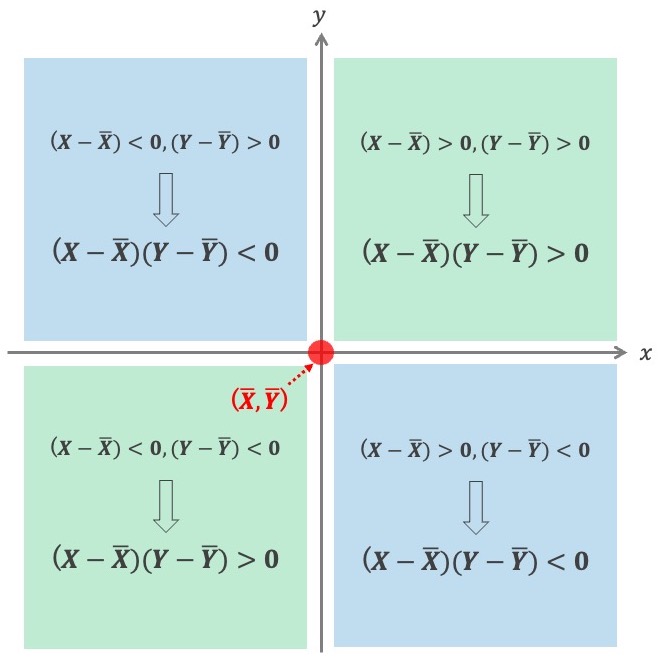
2行目の " "は、図形だと垂直の意味で使われると思いますが、ここでは「2つの変数に関連がない・互いに独立である」ということを意味する記号です*3。つまり、それぞれの観測点における誤差に一定の傾向はないということを仮定しています。例えば、「1日目の売り上げで期待値との誤差がプラス(=予想より売れた)とき、翌日の売り上げは必ず期待値よりも下になる」のように、他の観測点における誤差が情報を持ってしまう状況は、この仮定に違反しているということになります。
誤差に関する仮定をまとめると、
- 誤差の平均が0である
- 誤差は互いに関連がない(独立性, independentency)
- 誤差が正規分布する(正規性, normality)
- 誤差の分散が均一である(等分散性, homoscedasticity)
となります。
4つ目の等分散性は初出ですが、誤差が全て同じ正規分布に従うと仮定しているから、分散が同じになるのも当然の制約です。下の図ではXが大きくなるにつれて直線周囲のバラツキ方が大きくなっていますね。これは等分散性の仮定を満たしていないということになります。

おまけ:どうやって計算するの?
回帰分析の目的は、回帰直線の切片と傾きを推定することです。実際の計算は統計ソフトを使うので、手計算でできるようになる必要は全くないんですが、興味があれば読んでみてください。
前回の記事で、
このズレの総和が1番小さくなるような直線を選べば、みんな納得してくれそうです
と説明しましたね。「ズレ」とは期待値と観測値の差であり、これを残差(residual)と呼びます*4。 データ全体で残差を足し合わせると、プラスマイナスが打ち消しあって0になってしまうので、2乗して和をとります。分散のときと同じですね。
ここで、XとYには実際の観測値が入りますから、未知の変数は の2つですね。この2つの変数の関数であることが分かりやすいように、
と書いて変形していきます。
最小値を求めたいので微分します。 が最小となるような
を求めたい場合は、
のみ変数とみなして(
は定数と考えて)微分することを、
について偏微分する、といいます。
を
のそれぞれで偏微分すると、
両方が0になる点が最小値なので、下の連立方程式を解くと を最小にする
が求められます。
頑張って解くと、
となります(分子が共分散になる説明は割愛します)。 は、求めた
を使って、
で求められます。
おでん売り上げデータでは、
- n = 20
- ΣX = 312.3
- ΣY = 1645
- ΣX2 = 4920.03
- ΣY2 = 146891
- ΣXY = 25128.8
でしたので、これを代入すると、
となります。これは回帰直線の傾きが-12.8であることを意味していて、「最高気温が1℃上がると、おでんの売り上げは平均して12.8個減る」ということを意味しています。
この方法は、残差の2乗の和が最小になる係数を求めるので、「最小二乗法(least square method)」と呼ばれています。
おわりに
- 今回説明したモデルは、線形回帰モデル(linear model)と呼ばれ、応答変数が連続変数の場合に用いられるモデルです。「線形とは何か」は次回説明します。
- おまけのつもりが計算説明が長くなってしまいました。