分散分析(Analysis of Variance, ANOVA)を学ぶ目的でKutner先生のApplied Linear Statistical Models(5th edition)を拾い読みし始めました。今回は主に"Chapter 16: Single Factor Studies" から、分散分析の基本となる平方和・自由度の分割についてです。
ANOVAとは
似たもの同士を同じグループに分類すれば、グループ内は分ける前の全体の状態と比べて均一に近づきます。 意味のある分け方をすれば、バラツキを減らすことができるということです。 別の言い方をすれば、分類してバラツキが減らせたということは、対象物の特性について知ることができたということです。
ANOVAとはデータをグループに分類する(群分けする)ことでバラツキが減るかどうかを検証する方法です。ある変数で分類することでバラツキが統計的に有意に減ったのであれば、その変数はデータの特徴の一部を説明できているだろう、というロジックです。
例えば、下の図の場合はグループ分けすることでバラツキが減っているので、意味のある分類と言えます。

一方、下の図の場合はグループ分けしてもほとんどバラツキは変わっていませんので、この分類はデータの特徴の説明に役に立っていないと言えます。

群分けの方法は、割り付ける治療のように研究者が決めることもできますし、対象にそもそも備わっている特性で分類することもできます。なのでグループの呼び方は「群」の他に、治療あるいは処理(treatment)や、要因(factor)など文脈によって様々です。
セル平均モデル(cell means model)
ANOVAも回帰と同様に解析の際にモデルを想定しますが、セル平均モデルは最もシンプルなものです。
1つ目の式において、 はi番目の治療(要因)群に属するk番目の観測値を表しています。右辺の
はi番目の群の真の平均を表すパラメータ、
は真の平均と観測値との間の誤差です。
2つ目の式では、誤差が正規分布に従うことを示しています。属する群にかかわらず全ての誤差の分散は同じと想定されます。
3つ目の式では、それぞれの誤差が互いに独立であることを示しています。
変数が2つに増えると、それぞれの治療(要因)の効果を加法性や交互作用についての仮定が登場します。
また、群を決める変数が量的変数の場合は、群平均 と変数
の間に関数を想定して回帰モデルと考えることもできます*1。
平方和の分割
平方和とは
バラツキ具合の指標として、平方和(sum of squares, SS*2)を用います。平方和とは、平均と観測値との差の2乗(偏差平方)を足し合わせたものです。単純に平均と観測値との差を足し合わせると正負打ち消しあって0になってしまうので2乗してから足しています。
例えば、a種類の治療があって、いずれの治療群にもn個の観測値が属するとします。このときの総平方和(total sum of squares, SSTO)は、次の式で表されます。
ここで、 は平均を表しています。右下についている".."は「iについてもkについても特定のものを想起しない」という意味です。平均なのでkについて考えないのは当たり前ですが、「iも特定しない」としているので、
は群を分けない全体の平均であることを意味しています。逆に
と書けば治療群は特定しているので、i番目の治療群の平均値となります。
Σの添字を簡略化して、
と書いたり、(文脈上誤解がなければ)添字を省いたりすることもあります。
群間の平方和と郡内の平方和に分ける
i番目の治療群に属するk番目の観測値と全体平均との差を、次のように分解してみます。単にi番目の治療群に属する観測値の平均 を足して引いただけです。
両辺2乗します。
第2式は展開しただけ、第3式はΣを分配しただけです。
3行目の第2項において、 はkについて和を取るときは定数なので、Σの前に出すことができます(下式)。
ここで、 は平均と観測値の差を2乗せずに足し合わせているので0になり、第2項は消えます。
また、i番目の治療群に属する観測数を とすると、
となります( は
個の観測に対して共通だから)。
以上をまとめると、
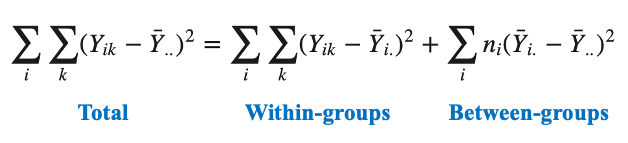
となります。
右辺第1項は「個々の観測値とそれが属する群の平均の差の平方和」なので、群内平方和と言います。グループ分けによって、群内は同じようなものの集まりとみなされることになるので、群内のバラツキは偶然誤差に起因すると考えられますので、群内平方和(sum of squares within groups)誤差平方和(error sum of squares, SSE)あるいは残差平方和(residual sum of squares, RSS)と呼ばれます。*3
右辺第2項は「群平均と全体平均の差の平方和」なので、群間平方和(sum of squares between groups)と呼ばれます。こちらは群の名前によって、当てられる略号は色々です(例:要因A→SSA, 治療→treatment sum of squares, SSTR)
自由度の分割
自由度とは
自由度(degree of freedom, df)は、変数の中で自由に値を決めることができる数のことです。例えば、3つの数a, b, cとその平均値mがあるとします。変数は4つですが、3つが決まると残りの1つの値は自動的に決まるので、この場合の自由度は3ということになります。
例として、r種類の治療があって、それぞれの治療群に 個の観測値が属していて、総観察数は
とします。ここで総平方和の自由度を考えてみます。
足し合される偏差平方は 個ありますが、偏差となる平均を求めるために自由度を1つ使うので、総平方和の自由度は
となります。
自由度も群間と郡内に分ける
平方和と同様に、自由度も群間と群内に分けてみましょう。
まず、群内の平方和では、 個の偏差平方と、基準となるr個の群平均があるので、自由度は
となります。
次に群間の平方和では、r個の群平均とそれらの偏差の基準となる全平均が1個あるので、自由度は
となります。
まとめると、
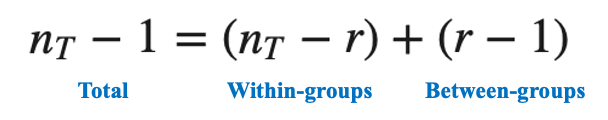
となり、自由度についても群内・群間に分けることができました。
平均平方
平方和を自由度で割ったものを平均平方(means square, MS*4)といいます。
誤差平均平方(mean square error, MSE)は誤差平方和(SSE)を自由度 で割ったものなので、
ここでi番目の群の標本分散を と書くと、
であり、各群の真の分散が等しく であると仮定すれば、
は
の不偏推定量(
)なので、
となり、MSEは誤差の分散σの不偏推定量となります。
治療の平均平方(treatment mean squares, MSTR)については、全ての群で観測数が等しいとすると、
となります(途中の計算は割愛しますが、Y=μ+εを使って群平均・全体平均を置き換えて式変形していきます)。
分散分析表
単にこれまで登場したものを表にまとめただけです。

もし全ての群で平均が等しければ、 は0になるので、MSEとMSTR(の推定するもの)は同じになるはずです。
データから計算されたMSEとMSTRが同じかどうか(比が1かどうか)を、F分布を使って統計的に検定してP値を計算します。
この先、固定効果・変量効果を考えるモデルが出てきます。解析上の違いがなかなか理解できなかったのですが、「MSE, MSTRの計算方法は同じだが、何を推定していると考えるかが違う」ということかなと思ってます。
おわりに
- 分類したがるのは人間の普遍的な本質だそうです*5。 分類すると未知の要素が減って安心する...なるほど、そうかもしれません。
- いつもにも増して説明がスカスカになってしまいました(自分の勉強の記録ということで...)。
- 猫タワーの傾きがひどくなってきていて心配です。
")