広い意味で予測モデルを含め、検査は真の状態を言い当てることを目的として行われる。 「真の状態」が現時点のことであれば「診断」になるし、未来のことなら「予後予測」になる。 検査の性能は次の2つに分けて評価する。
- 識別能(discrimination):病気がある人・ない人、あるいはイベントを発生する人・しない人を正しく区別する能力
- 較正能(calibration):予測と実際に観察された状態がどれくらい一致するか
識別能の指標としては、ROC曲線下面積(area under the ROC curve, AUROC)、あるいは一般的な呼び方ではc統計量(c-statistics)があり、これについては以前述べた。
ここでは較正能の評価として、rmsパッケージを使って較正プロット(calibration plot)を描いてみる。
パッケージとデータセットの準備
ROC曲線の解説で使ったpROCパッケージ内のaSAHデータセットを使う。 これはクモ膜下出血(subarachnoid hemorrhage, SAH)で入院した患者の入院時の血漿マーカーが予後を予測できるかを調べた研究のデータ。
library(rms) library(pROC) library(tidyverse)
アウトカムがGood, Poorで与えられているので、後々のことを考えてGood=1, Poor=0として変数名をyとしておく。
また、元のデータをモデル開発用(development)ということでdev_dataとしておき、モデル検証用(validation)の外部データのつもりでブートストラップサンプルを作ってval_dataとしておく。
dev_data <- aSAH %>% mutate(y = if_else(outcome=="Good",1,0)) val_data <- dev_data %>% sample_n(size = nrow(.), replace=TRUE)
ロジスティック回帰モデルを当てはめる
共変量にageとgenderを使ったモデルを当てはめた。
fit <- glm(y ~ age + gender, data = dev_data, family = binomial(link="logit"))
この予測モデルで予測されるアウトカム発生確率(=Goodの確率)を、開発用・検証用それぞれのデータセットで求めてpredという名前をつけた。
dev_data$pred <- predict.glm(fit, type = "response") val_data$pred <- predict.glm(fit, newdata = val_data, type = 'response')
dev_dataについてはfit$fitted.valueで求められるが、対比がわかりやすいように上記のように書いた。
var.prob( )を使って較正プロットを描く
まずは予測値と観測値を指定する必要がある。
p,logit:予測される確率p、または対数オッズlogitのデータを渡す。どちらかを指定。y:観察されたアウトカムを渡す
較正プロットでは対象集団をいくつかに分割して、それぞれのグループで観察されたアウトカムの割合を計算して使うので、下のいずれかの方法で分け方の指定が必要。
g:分割するグループ数。m:グループ数ではなくグループのサイズで指定したいとき。cuts:区分する境界値を指定したいときはcuts = c(0,0.1,0.8,0.9,1)のように指定する。
作図される項目については以下の引数を指定(デフォルトは全てTRUE)。
pl:そもそもcalibration plotを作成するかどうかsmooth:p, yの平滑化曲線をlocally-weighted scatter plot smoother(lowess) を使って描くかどうか(点線曲線)logistic.cal:p, yのlinear logistic calibration fitを描くかどうか(実線)riskdist:全体を101個に分割した相対頻度を髭ヒストグラムで描くかどうか。FALSEにすると描かないはずだが受け付けられずエラーになる。
作図項目については上記の他に、
connect.group:TRUEとするとグループ毎のプロットを折れ線で繋ぐ。デフォルトはFALSEconnect.smooth:FALSEとするとp,yの平滑化曲線の代わりに点でプロットするevaluate:lowessのポイント数。デフォルトは100
が指定できる。
軸や凡例に関しては、以下のとおり。
xlab,ylab:軸ラベルlim: x, y軸の範囲legendloc: 凡例の位置. locator(1)でマウスを使って指定。FALSEとすると表示しないcex:文字の大きさ:デフォルトは0.7mkh:凡例のシンボルの大きさ(mark heightの略?)デフォルトは0.02lwd.overall: 線の太さflag: TRUEとすると指標が意味があるときに*マークをつける。Chisq2, B Chisqは<0.01のときに*がつく。
val.prob(p = dev_data$pred, y = dev_data$y, g=10)
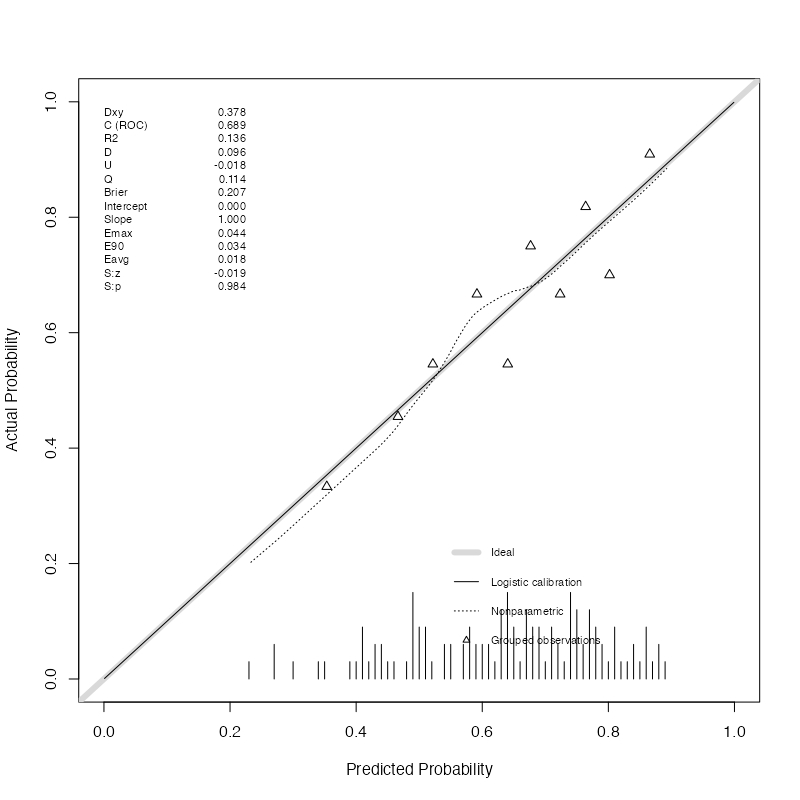
実線は開発モデルを使って計算された予測確率pのlogitを説明変数として、アウトカムyをロジスティック回帰モデルで回帰したもの
なので、ここではピッタリ当てはまっていて当たり前。
次は検証データで。
val.prob(p = val_data$pred, y = val_data$y, g=10)

こちらのlinear logistic calibration fit(実線)は S字に歪んでいる。
表示される性能指標
以下の指標が計算される。これらは分割するグループ数(gで指定)には依存しない(説明中のnは分割するグループ数ではなく観察例数)。
Dxy:ソマーズのD(Somers'*1)は順序変数間の相関を表す指標で、-1から+1の範囲の値を取る。同順位がなければケンドールの
と同じになる。c統計量とは
の関係が成り立つ。
C(ROC):ROC曲線下面積(AUROC)。より一般的にはc統計量と呼ぶ。前述のとおり、の関係が成り立つ。
R2:Nagelkerke-Cox-Snell-Maddala-Magee [tex: R2] index。モデル全体の当てはまりの指標。Cox-Snell pseudo-[tex: R2]と同じ(?)。D:判別指数D(discrimination index)= (D:Chi-sq-1)/n- `D:Chi-sq":-2{(帰無モデルの対数尤度) - (開発モデルの対数尤度)} で計算される。尤度比検定でつかわれる逸脱度(deviance)のこと。
D:p:上記の尤度比検定のP値U:unreliability index U = (U:Chi-sq- 1)/nU:Chi-sq:-2{(切片=0,傾き=1のモデルを当てはめたときの対数尤度)-(新たに当てはめたモデルの対数尤度)} で計算される。前者は最初に開発されたモデルに当てはめたとき、後者はそのデータで当てはめたとき(=recalibrationしたとき)の対数尤度。U:p:上記の検定量が自由度1のカイ2乗分布に従うとして計算したP値Q:quality index Q = D - UBrier:ブライアスコア(pとyの差の2乗の平均値)Intercept:linear logistic calibration fitの切片(calibration intercept)Slope:linear logistic calibration fitの傾き(calibration slope)Emax:予測確率とLOESSを使って較正された確率(点線)の差の最大値。probabilitiesE90:上記の90パーセンタイル値Eavg:上記の平均値S:z:較正精度のSpiegelhalter Z-testのZ値(計算は下の式を参照)S:p:上記のP値
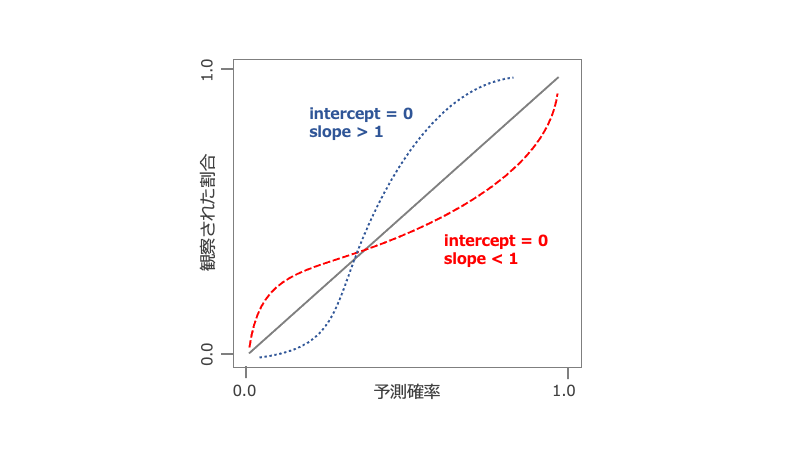
Calibration intercept & slope*2の解釈
完璧に当てはまっているときはintercept=0, slope=1となる。
Interceptは全体的なズレを評価。
- Intercept > 0のとき:
開発したモデルで予想される確率よりも、検証データで観察される発生確率の方が、全体的に高いということになる(= 開発したモデルはリスクを過小評価) - Intercept < 0のとき:
開発したモデルで予想される確率よりも、検証データで観察される発生確率の方が、全体的に低いということになる(= 開発したモデルはリスクを過大評価)

Slopeは予測確率が上がったときにどれくらいズレてくるか(予測確率の高低による変化)。
- Slope > 1のとき:
予測確率が十分上がる前に、実際に観察される確率が高くなってくる("not extreme enough"と表現) - Slope < 1のとき:
予測確率が十分上がっても、実際の観察される確率はそれほど高くない("too extreme"と表現)
おわりに
- rmsパッケージにはブートストラップで内的妥当性検証をする関数もあるが、それはまた別の機会に。
- 地域ネコのTVコマーシャルが流れてました。昔からあったのか、自分が気にするようになったのか。
参考資料
予測モデルの大家(たいか)、Steyerberg先生の予測性能指標に関する総説。
Steyerberg EW, Vickers AJ, Cook NR, Gerds T, Gonen M, Obuchowski N, Pencina MJ, Kattan MW. Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology. 2010 Jan;21(1):128-38. doi: 10.1097/EDE.0b013e3181c30fb2. PMID: 20010215; PMCID: PMC3575184.Calibration curveの見方が分かりやすく説明されている。
Van Calster B, McLernon DJ, van Smeden M, Wynants L, Steyerberg EW; Topic Group ‘Evaluating diagnostic tests and prediction models’ of the STRATOS initiative. Calibration: the Achilles heel of predictive analytics. BMC Med. 2019 Dec 16;17(1):230. doi: 10.1186/s12916-019-1466-7. PMID: 31842878; PMCID: PMC6912996.